LLMs + Vulnerability-Lookup: What We’re Testing and Where We’re Headed
#AI#NLP#LLM#Text-Generation#Text-Classification#Datasets#HuggingFace
Everyone’s talking about AI, NLP and LLMs these days, and, to be honest, so are we!
Recently, we’ve been exploring how LLMs can help us make sense of the massive amount of vulnerability data we collect and improve vulnerability management—while always remembering that AI is just a tool, not a solution on its own!
The picture below gives a glimpse of what we’ve tested so far.
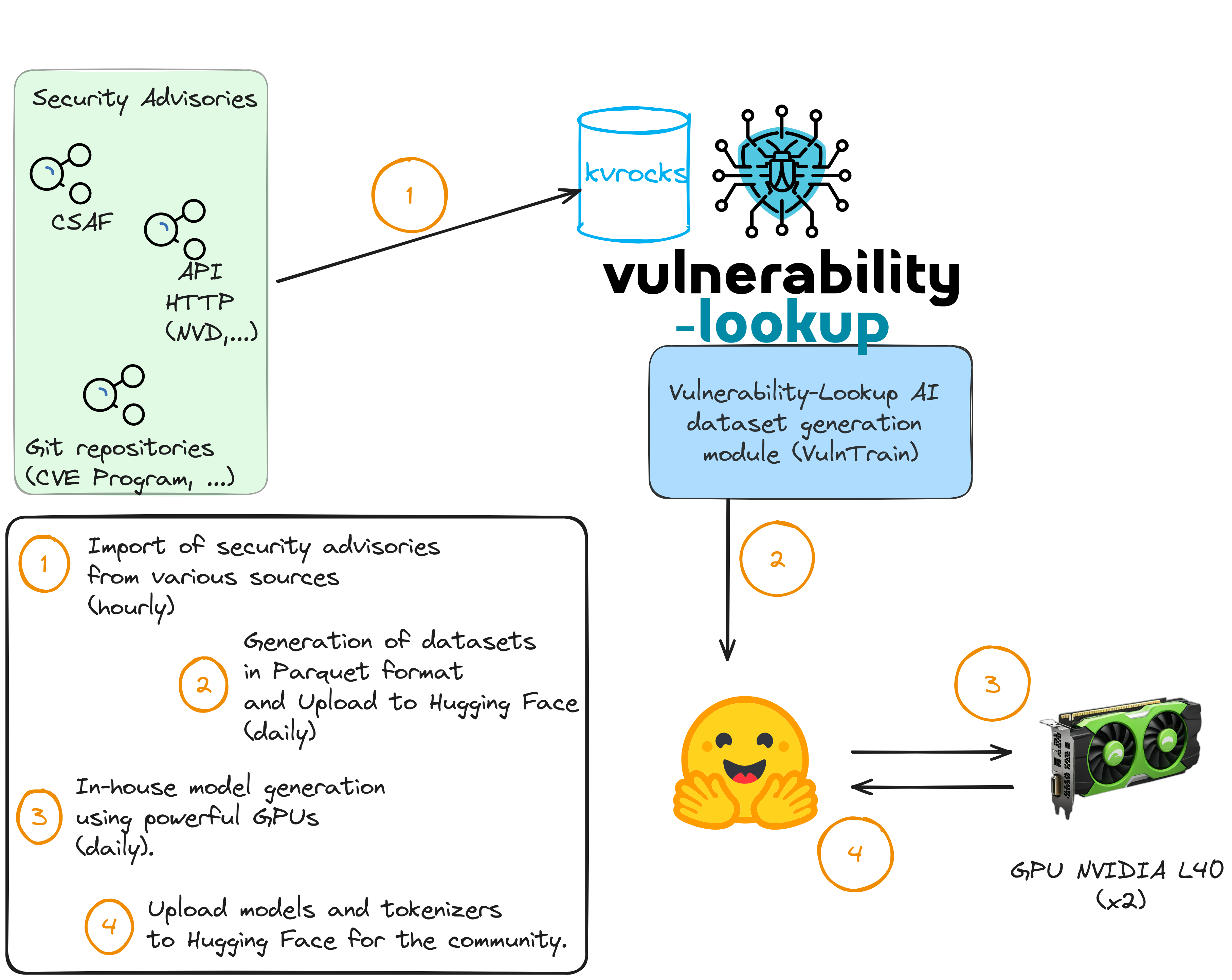
With the various vulnerability feeders of Vulnerability-Lookup (for the CVE Program, NVD, Fraunhofer FKIE, GHSA, PySec, CSAF sources, Japan Vulnerability Database, etc.) we’ve collected over a million JSON records! This allow us to generate datasets for training and building models! 🚀
During our explorations, we realized that we can automatically update a BERT-based text classification model daily using a dataset of approximately 450k rows from Vulnerability-Lookup. With powerful GPUs, it’s a matter of hours.
As always, we aim to support the community, which is why all components of this experiment are open source:
- Collected data with daily dumps.
- Datasets (updated daily), ready to use with your NLP trainers, along with our model. Available on Hugging Face.
- Our own LLM trainers.
We have plenty of ideas to go further (the missing step 5 in the picture), including:
- Guessing CPE names using a different approach than CPE Guesser
- Affected Product/Category Classification
- Vulnerability Type Classification, using CWE mappings
- Automated Threat Intelligence Tagging, using existing ATT&CK mappings
- Estimating exploitability based on available data in vulnerabilities
- Generating models for the Japan Vulnerability database or for the feed CSAF NCSC-NL
- …
The list is long and we welcome your ideas!
Demonstration
For a quick demo, check out our vulnerability classification space:
👉 https://huggingface.co/spaces/CIRCL/vulnerability-severity-classification
This is a demo of our text classification model with a mapping on CVSS scores.
It is a fine tuned model based on distilbert-base-uncased, trained with our hardware (2X GPUs NVIDIA L40).
We will test various BERT-based model, and of course RoBERTa.
If your interested in text generation, we’ve trained a larger model to assist in writing vulnerability descriptions, using GPT-2 as base. You can find it on Hugging Face, along with usage information.
For a real usage, we recommend running it locally with Ollama and Open WebUI.
Contributions
If you’re interested in contributing with your ideas, join us in Luxembourg on April 8-9, 2025:
Examples
On Hugging Face
Below, a couple of examples from the space on Hugging Face.
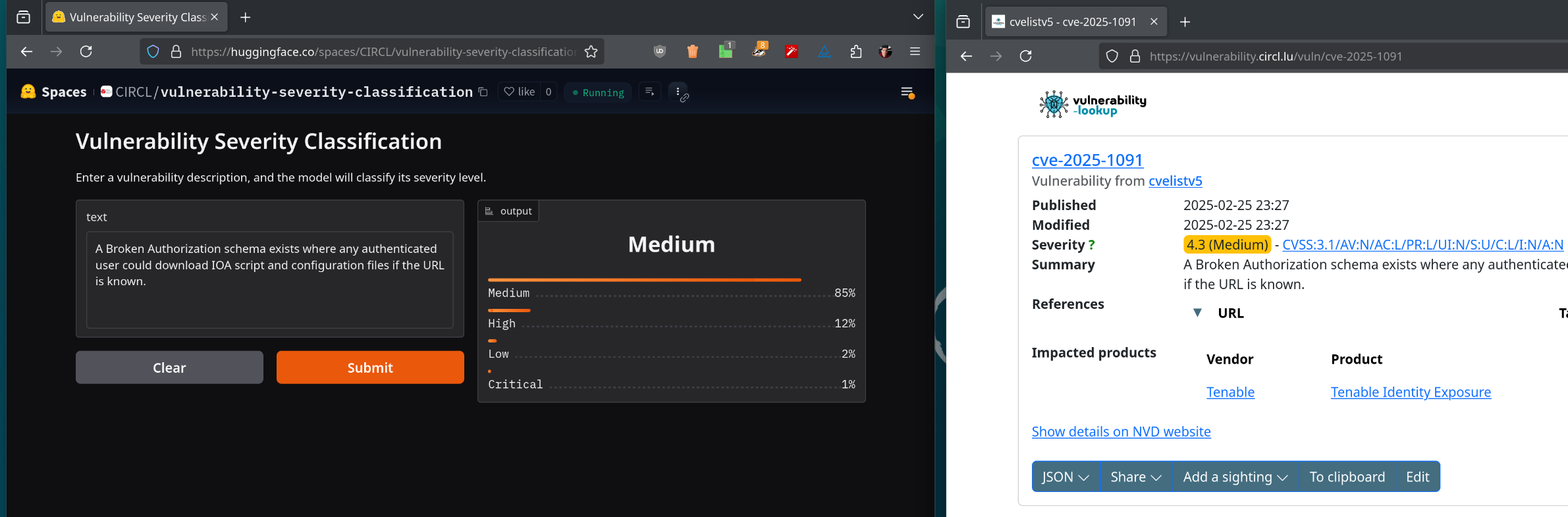
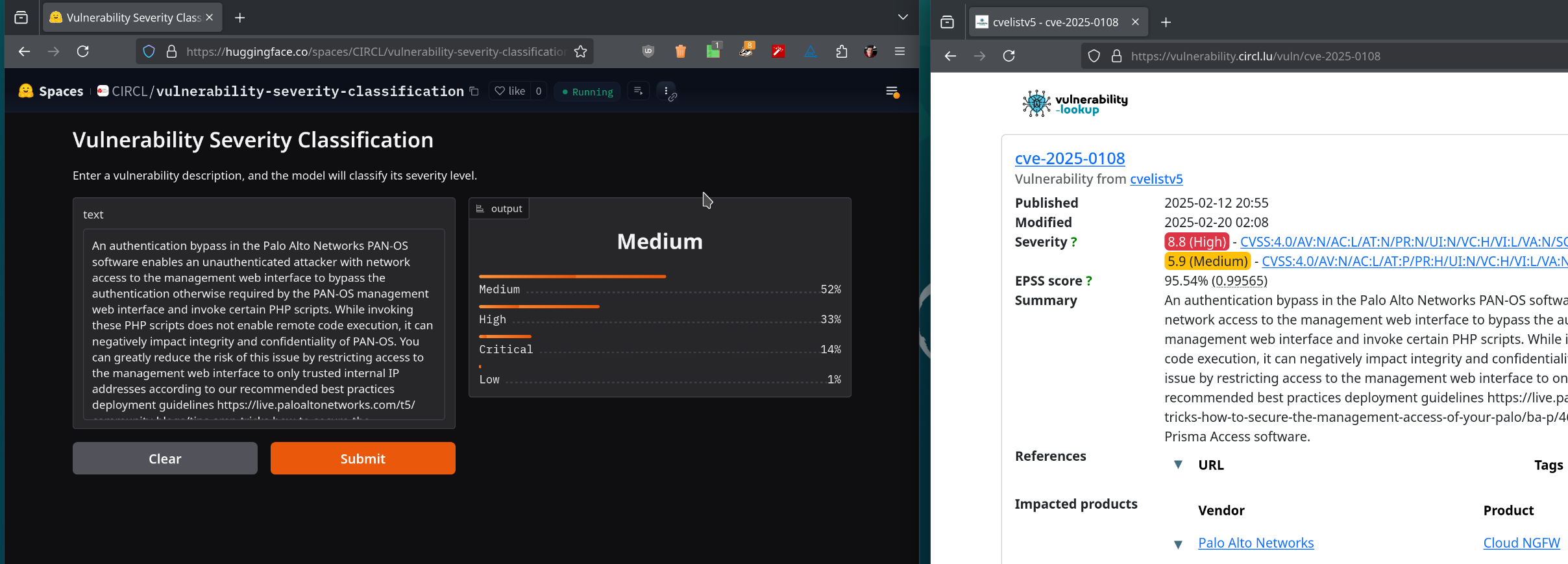
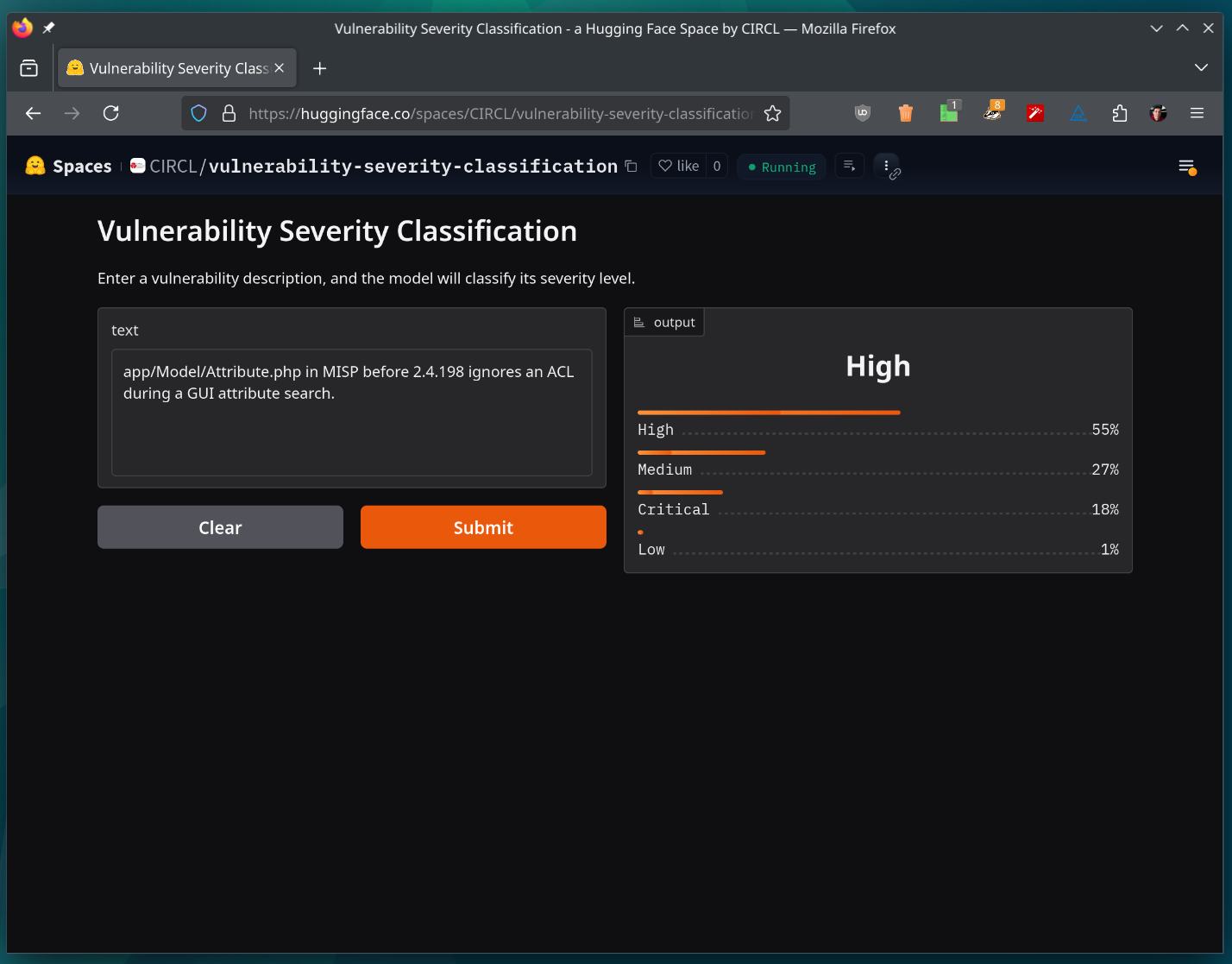
With Python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
model_name = "CIRCL/vulnerability-severity-classification-distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval()
# Example test input
test_description = "app/Model/Attribute.php in MISP before 2.4.198 ignores an ACL during a GUI attribute search."
inputs = tokenizer(test_description, return_tensors="pt", truncation=True, padding=True)
# Run inference
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
# Print results
print("Predictions:", predictions)Acknowledgments
This work is made possible thanks to funding from Europe through the NGSOTI project. And of course thanks to all the contributors!